深度解读 · 模型训练 / 后训练
在线策略蒸馏:用十分之一的成本,逼出强化学习的效果
Thinking Machines Lab 的 On-Policy Distillation——把"强化学习的对路"和"蒸馏的密集反馈"合二为一。一个看似简单的改动(换掉正则项里的那个模型),把后训练成本砍掉 10~30 倍。
原文:Thinking Machines Lab · Connectionism · 2025.10.27 · 作者 Kevin Lu · 基于 Tinker 训练 API
核心思想一图看懂: 学生模型自己生成回答(在线采样),由高水平老师模型对学生写下的每一个 token 逐字打分,把"强化学习的对路"与"蒸馏的密集反馈"合二为一。图片来源:Thinking Machines Lab《On-Policy Distillation》
一句话抓住重点
训练小模型有两条老路:RL(强化学习) ——让模型自己答、只告诉它对错,对路但反馈太稀疏 ;SFT/蒸馏 ——让模型模仿老师的标准答案,反馈密集但学的是老师的处境、不是自己的 。在线策略蒸馏的核心:让学生自己答题,但请老师给它写的每一个 token 打分 。结果——既对路又密集,AIME 数学推理达到同等水平只花 RL 1/10 的算力。
01 · 背景
训练专家模型的三个阶段,卡在最后一关
一个能力强的小模型,是几层训练叠出来的:
📚
预训练 Pre-training
教通用能力:语言、广义推理、世界知识
🏥
中训练 Mid-training
灌领域知识:代码、医学库、公司内部文档
🎯
后训练 Post-training
塑目标行为:指令遵循、数学推理、对话
💡
为什么用小模型
可本地部署(隐私/安全)、更新快、推理便宜
最后一关"后训练"决定成败,而它只有两种打法——而这两种各有硬伤。
02 · 核心矛盾
RL vs 蒸馏:一个对路但瞎,一个清楚但跑偏
文章用下棋 打了个绝妙的比方,一看就懂:
♟️ 学棋的三种方式
· On-policy RL(强化学习) = 自己下整盘棋、无人指导,只在终局知道输赢——反馈
对路 (是你自己的棋),但
极稀疏 ,不知道哪一步是败着。
· Off-policy 蒸馏 = 看大师下棋,每一步都很强——反馈
密集 ,但那些局面
新手根本遇不到 ,学了用不上。
· On-policy 蒸馏(本文) = 你自己下,请大师
对你走的每一步 从"昏招"到"妙手"逐一点评——既是你的棋,又步步有评分。
① 强化学习(On-policy RL): 学生自己跑完整条轨迹,只在终局 拿到一个对/错的奖励信号。轨迹是自己的(对路),但反馈极稀疏——不知道究竟哪一步走错了。
② 离线蒸馏(Off-policy): 学生学习老师生成的轨迹,每一步都有密集监督。但这些"高水平局面"是老师的处境,学生自己根本走不到 ,存在分布错配与误差累积。
③ 在线策略蒸馏(本文): 学生自己采样轨迹,老师对学生写下的每个 token 逐一打分。轨迹是自己的(在线、对路),反馈又密集——两全其美。
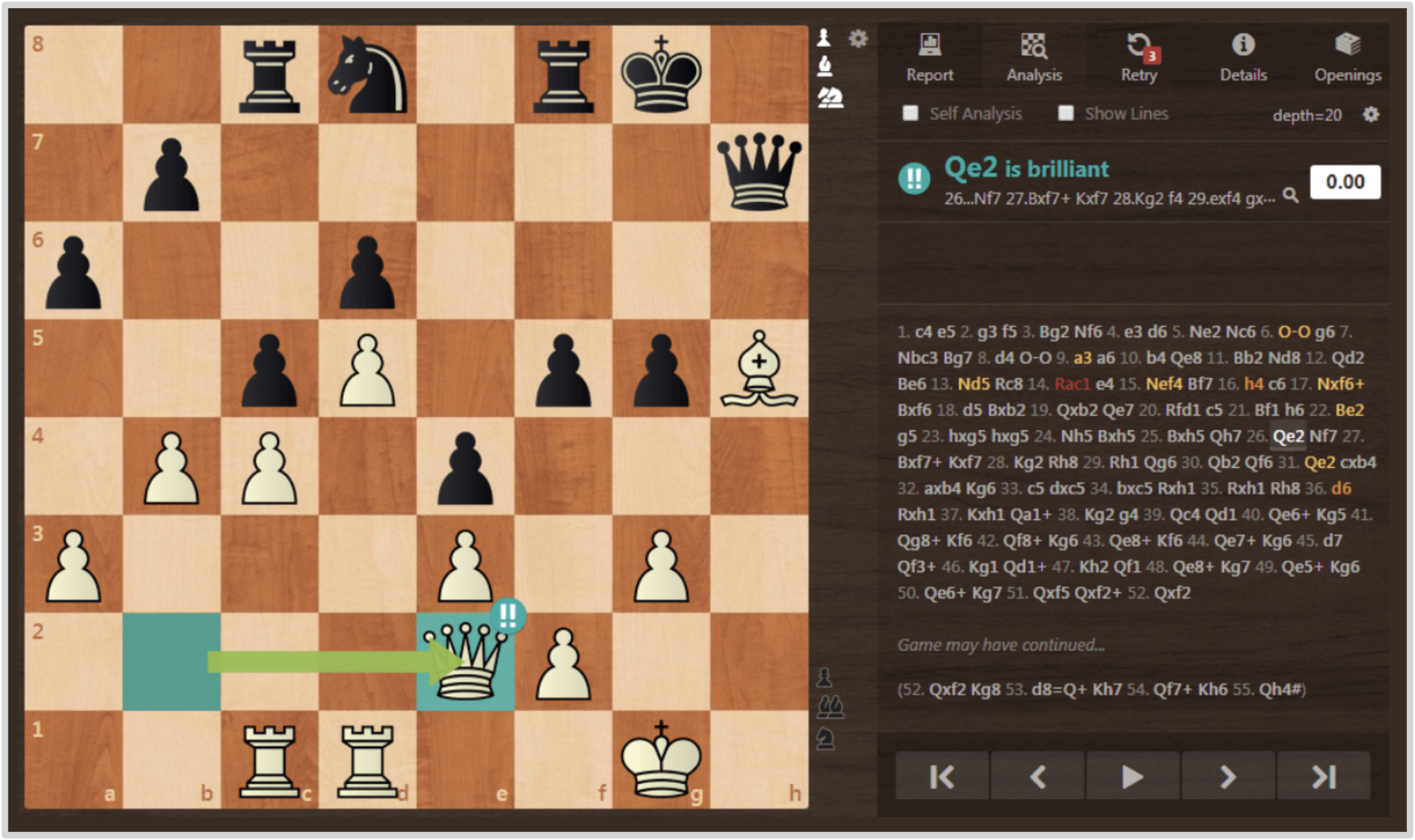
来自 chess.com 的对局分析截图:分析引擎会给每一步棋 逐一标色——红色=失误(blunder) 、橙色=错误、黄色=不准确、蓝色=妙手(brilliant) 。在线策略蒸馏就像这样一位"逐步点评的大师",对学生自己走的每一步给出密集评分。
SFT / 离线蒸馏
模仿外部标准答案
采样:离线(老师的) 反馈:密集 ✓ 痛点:误差累积、学到老师的腔调却没学到事实准确性
强化学习 RL
自己答、只评对错
采样:在线(自己的)✓ 反馈:稀疏(每轮仅 O(1) bit) 痛点:不知错在哪、算力多花在"搜索"上
在线策略蒸馏
自己答、老师逐 token 评分
采样:在线(自己的)✓ 反馈:密集(每轮 O(N) bit)✓ 两全其美
03 · 怎么做
机制:让老师当"逐字裁判"
具体做法:从学生模型 采样轨迹(让它自己答),再用一个高水平老师模型 给每个 token 打分 。打分用的是逐 token 反向 KL 散度 ——衡量在同样的上文下,学生和老师对下一个词的分布差多远。学生表现得和老师一模一样时,KL=0。
$$\text{KL}\Bigl(\pi_\theta \lvert\rvert \pi_\text{teacher}\Bigr) = \mathbb{E}_{x \sim {\pi_\theta}} \Bigl[ \log \pi_\theta(x_{t+1} | x_{1..t}) - \log \pi_\text{teacher}(x_{t+1} | x_{1..t}) \Bigr]$$
白话解读: 在学生自己生成的轨迹($x \sim \pi_\theta$ )上,对每个位置比较"学生认为下一个词的概率"与"老师认为下一个词的概率",取对数之差求期望。差得越多惩罚越大;学生与老师对每个 token 的分布完全一致时,这个反向 KL 就降到 0。它就是逐 token 的"逐字评分"。
一条由老师模型打分的学生轨迹示例:颜色越深的红色 token,对应越高的反向 KL (即学生在该处与老师分歧越大、越"昏招")。这正对应前面的下棋类比——老师给学生自己走的每一步都标上了"评分热力图"。
💡 为什么反向 KL 是聪明的选择
①
不可"刷分"(unhackable) :低 KL 必然对应老师眼中"高概率的好行为",没法投机;
②
mode-seeking(抓主峰) :只学老师那一种最优行为,不把概率摊给一堆次优选项;
③
省算力 :不用等整条轨迹采样完才算奖励,可用更短/部分轨迹训练;查老师的 logprob 只需大模型跑
一次前向 ,轨迹则由便宜的小学生生成——还不需要单独的奖励模型。
🔧 工程上有多简单
文章原话:在已有的 RL 实现上,这可以是
"一行改动" ——只要那套 RL 用了 KL 正则,把
正则项里的那个模型换成老师模型 即可。把每个 token 的优势值(advantage)设成"负的反向 KL",复用 RL 的 importance-sampling 损失做更新。已开源在
Tinker cookbook。
04 · 数据说话(一)
数学推理:复刻 Qwen3 结果,1/10 算力
在 Qwen3-8B 上训数学推理(老师 Qwen3-32B),目标把 AIME'24 从 60% 提到 70%。三条路的代价对比一目了然:
方法 AIME'24 GPQA-Diamond GPU 小时
离线蒸馏 (SFT) 55.0% 55.6% — + 强化学习 RL 67.6% 61.3% 17,920 + 在线策略蒸馏 74.4% 63.3% 1,800
数据来自 Qwen3 技术报告 Table 21。在线策略蒸馏不仅分数更高 ,GPU 小时只有 RL 的 1/10 。TM 用 Tinker 复现:从 SFT-400K 检查点出发,约 150 步(~7.7 万 prompt)就到 70%。
在线策略蒸馏过程中的 AIME'24 得分曲线(横轴为额外训练算力 FLOPs)。在线策略蒸馏的算力效率显著高于 SFT ,对 LoRA 模型尤其明显:在 rank=32 时,做完 SFT 后 LoRA 仍落后全量微调 13% ,但做完在线策略蒸馏后差距收窄到仅 6% 。
05 · 数据说话(二)
个性化:先灌知识,再"找回"被冲掉的能力
第二个场景更贴近企业落地:训一个懂公司内部文档 、同时会好好聊天/遵循指令 的内部助手。难点在于——给模型灌新知识(中训练)会冲掉它原有的指令遵循能力 ,这叫"灾难性遗忘"。无论怎么混比例、用 LoRA 限制,都救不回 IF-eval。
在线策略蒸馏给了个漂亮解法:拿这个模型自己更早的版本当老师 ,在 Tulu3 对话 prompt 上做一遍在线蒸馏,把丢掉的指令遵循能力"重新唤醒"——而且不损失新学的知识 。
模型阶段 内部知识 (Internal QA) 对话能力 (IF-eval)
Qwen3-8B 原版 18% 85% + 中训练 (100% 文档) 43% 45% ↓崩 + 中训练 (70% 混合) 36% 79% + 中训练(70%) + 在线蒸馏 41% 83% ↑救回
💡 这才是最有想象力的地方
"用模型自己的旧版本当老师,找回被冲掉的能力"——这等于把模型本身当成了奖励模型。它指向一个很实用的范式:
持续学习(continual learning) 。可以"灌新知识 → 蒸馏找回行为"两个阶段反复交替,让模型不断更新知识、又不退化。对企业内部那种"文档天天变、又要保持好用"的助手,这是教科书级的解法。
06 · 为什么便宜
一个反直觉的结论:RL 的钱主要花在"搜索"上
为什么蒸馏能用 1/10 的步数追平 RL?文章给了个深刻解释:
RL ≈ 搜索(探索语义策略空间)
蒸馏 ≈ 学习(直接学会最终策略)
RL 的算力大部分不花在梯度更新上,而花在"搜索" ——不断 rollout、试错、分配信用,靠运气"撞"到好策略。但一旦好策略被找到,把它教给别人就简单多了 。在线策略蒸馏是抄近路:它不需要重走 RL 那条曲折的探索曲线,只学最终那个策略 。
从同一初始化出发,在线策略蒸馏只需约 1/7 ~ 1/10 的梯度步就能学会 RL 训练出来的策略——换算成算力即约 50~100 倍的效率提升 。印证了"RL 的成本主要花在搜索、而学习一个已知策略要便宜得多"这一结论。
🧪 还有两个意外发现
① 单 prompt 也能学 :只用
一道 随机选的数学题反复训 20 步,竟也能逼近老师的 AIME 成绩——因为它学的是老师的"完整分布",不是死记一个答案(RL 多 epoch 训同一题会退化成背答案)。
② 连"自己的样本"做 SFT 都会变差 :在 KL=0 的自采样数据上做 SFT,任何 >0 的学习率都会让性能下滑——因为有限 batch 的微小分布偏差会让训练逐渐"跑偏成离线"。而在线蒸馏因老师固定、始终在线,
不会退化 。这正是它适合持续学习的根因。
07 · 总评
这篇文章的分量在哪
💡 我的总评
在线策略蒸馏本身
不是 TM 的原创 (Qwen3 团队、Agarwal 等早有相关工作),TM 的贡献是把它
讲透、跑通、开源 ,并用一系列干净的实验把"为什么有效"说清楚——尤其是"
密集反馈带来数量级的效率提升 "和"
它是持续学习的天然工具 "这两点。对你做训练框架(/projects/trainer)的人来说,这篇的可操作性极强:核心是"换掉 KL 正则里的模型",几乎零额外工程,却能把后训练成本砍一个数量级。
落地门槛低 + 收益大 ,是少见的"读完就能用"的研究博客。
🔗 与另一篇的呼应
文中明确提到:要做到"真正的 on-policy",需要训练端和采样端
逐比特一致 ——这正是 TM 另一篇《消除 LLM 推理的不确定性》要解决的问题。两篇是一套组合拳:
那篇打地基(确定性),这篇盖楼(蒸馏) 。